Configure Chef Habitat On-Prem Builder for disaster recovery or a warm spare deployment
To quickly recover from an outage or perform planned upgrades or maintenance, you can use a warm spare or disaster recovery installation.
High availability
The only supported high availability solution is to use SaaS backend services, such as AWS RDS and AWS S3. There is no fully on-premises solution for highly available Habitat Builder services.
Configure disaster recovery or warm spare
The following architecture diagram shows how data synchronization increases the availability of the Builder API and backend for disaster recovery and warm spare scenarios.
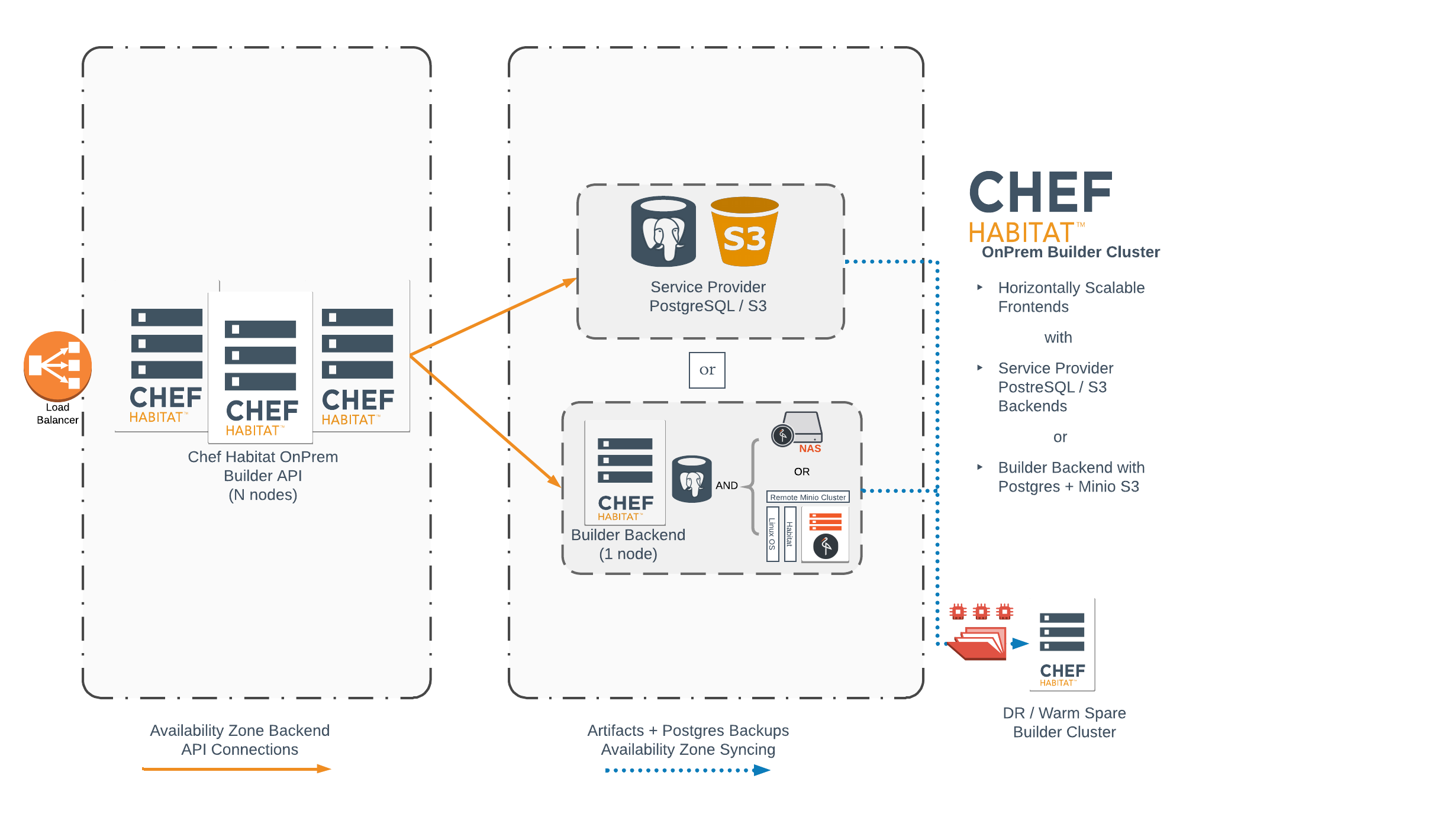
Synchronize components
To enable a disaster recovery or a warm spare deployment, provision the same number of frontend and backend systems as your primary location. These systems serve as your disaster recovery or warm spare environment. For disaster recovery, deploy them in a separate availability zone with separate storage.
Builder stores lightweight data, so backup and disaster recovery or warm spare strategies are straightforward. Habitat Builder has two types of data you should back up in case of a disaster or when transferring workloads to a warm spare:
- PostgreSQL package and user metadata
- Habitat artifacts (
.hartfiles)
Back up or replicate all data using highly available storage systems as described in the following sections.
Coordinate the entire On-Prem Builder cluster backups to happen together.
However, because Builder stores only metadata and artifacts, you have some flexibility in backup timing.
If a package’s metadata is missing from PostgreSQL, you can repopulate it by re-uploading the package with the --force flag.
For example:
hab pkg upload <PATH_TO_HART_FILE> -u <ON_PREM_URL> --force
PostgreSQL
If you use AWS RDS, take periodic snapshots of the RDS instance. For disaster recovery, use a Multi-AZ RDS deployment.
For non-RDS deployments, back up PostgreSQL data as described in the Habitat Builder PostgreSQL documentation.
Periodically restore backups into the disaster recovery or warm spare environment using a scheduled automated process, such as a cron job. You can run the restore remotely from the same host that created the backup. The Builder database is typically small, usually only tens of megabytes.
Habitat artifacts
Habitat artifacts are stored in one of two locations:
- MinIO
- S3 bucket
If your backend uses MinIO for artifact storage, make sure it is backed by highly available storage. Back up MinIO data as described in the Habitat Builder MinIO documentation. If you use a warm spare in the same availability zone or data center and the filesystem is network-attached, you can attach it to the warm spare. However, only one Builder cluster should accept live traffic when sharing the same filesystem. For disaster recovery, replicate the filesystem to the alternate availability zone or data center.
If artifacts are stored in an S3 bucket, you can use the same bucket for a warm spare in the same availability zone or data center. For disaster recovery, replicate the S3 bucket to the alternate availability zone or data center. AWS S3 provides built-in replication for this purpose.
If you don’t re-attach the MinIO filesystem to the warm spare, periodically restore backups into the disaster recovery or warm spare environment using a scheduled automated process, such as a cron job.